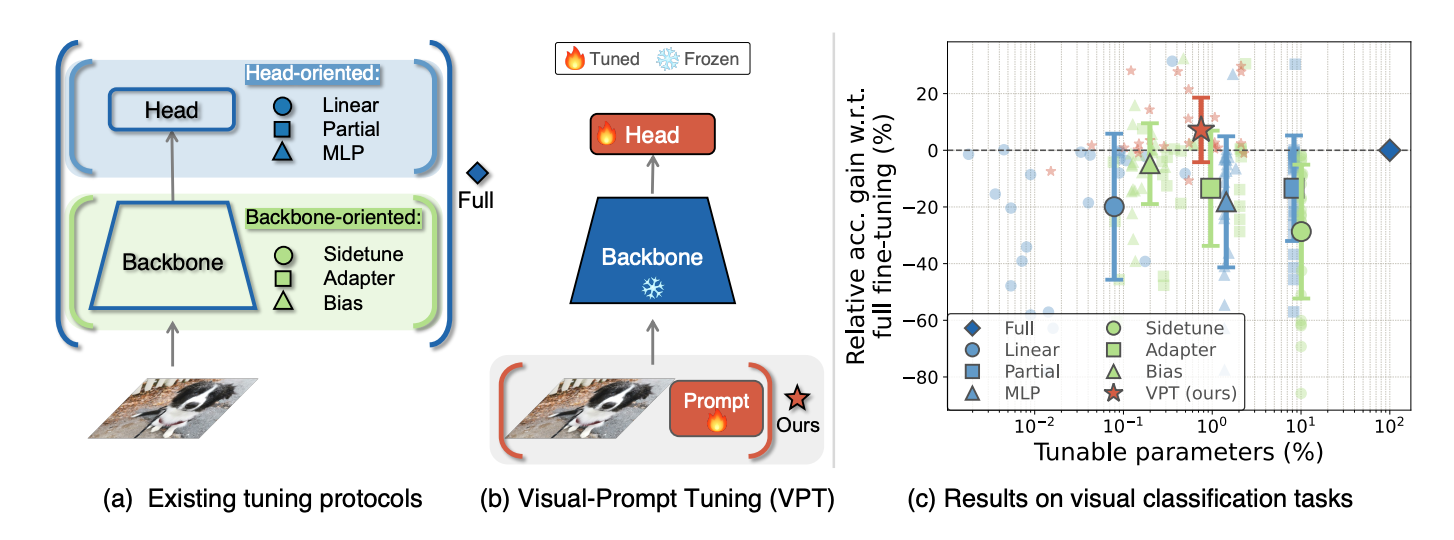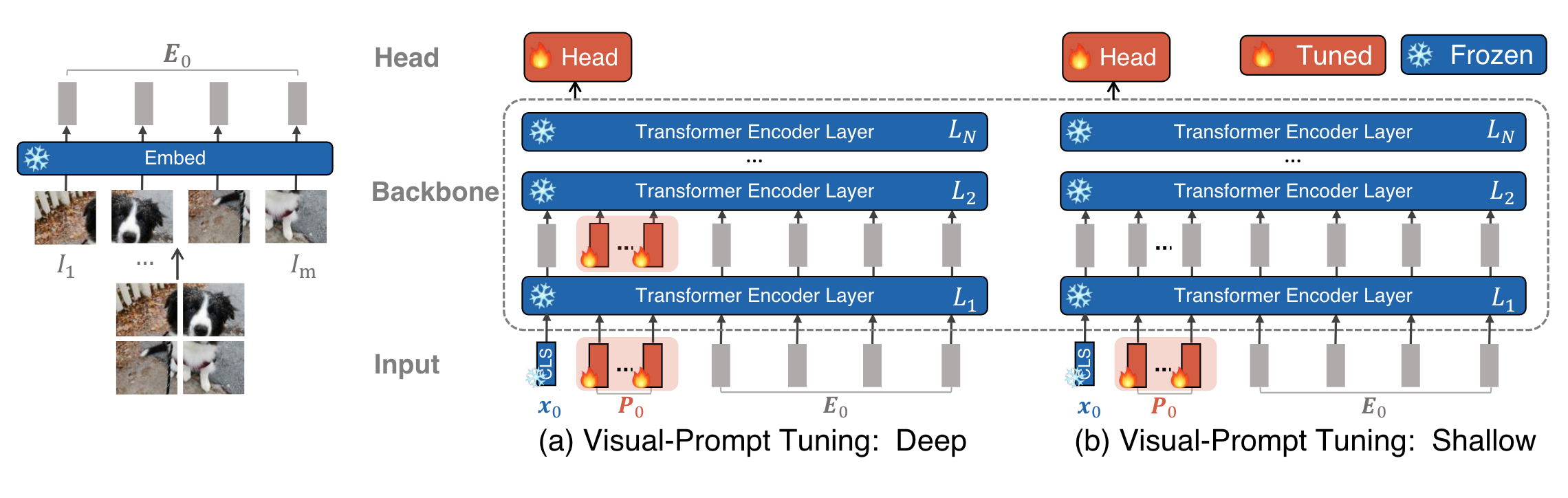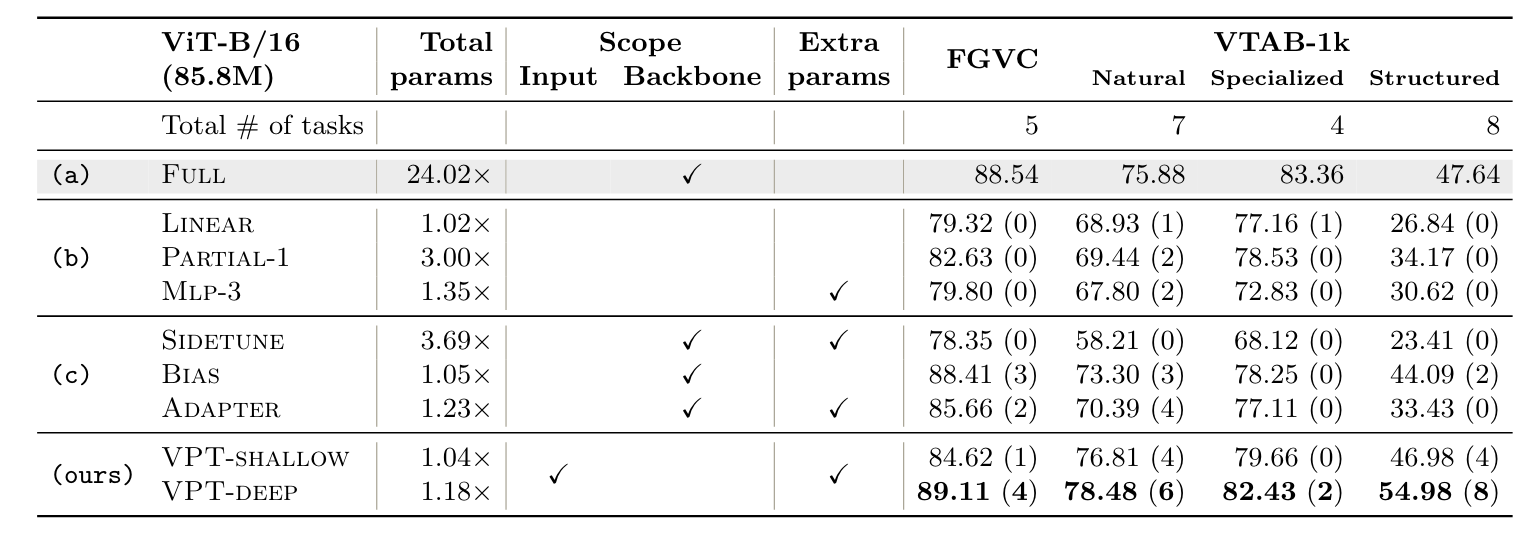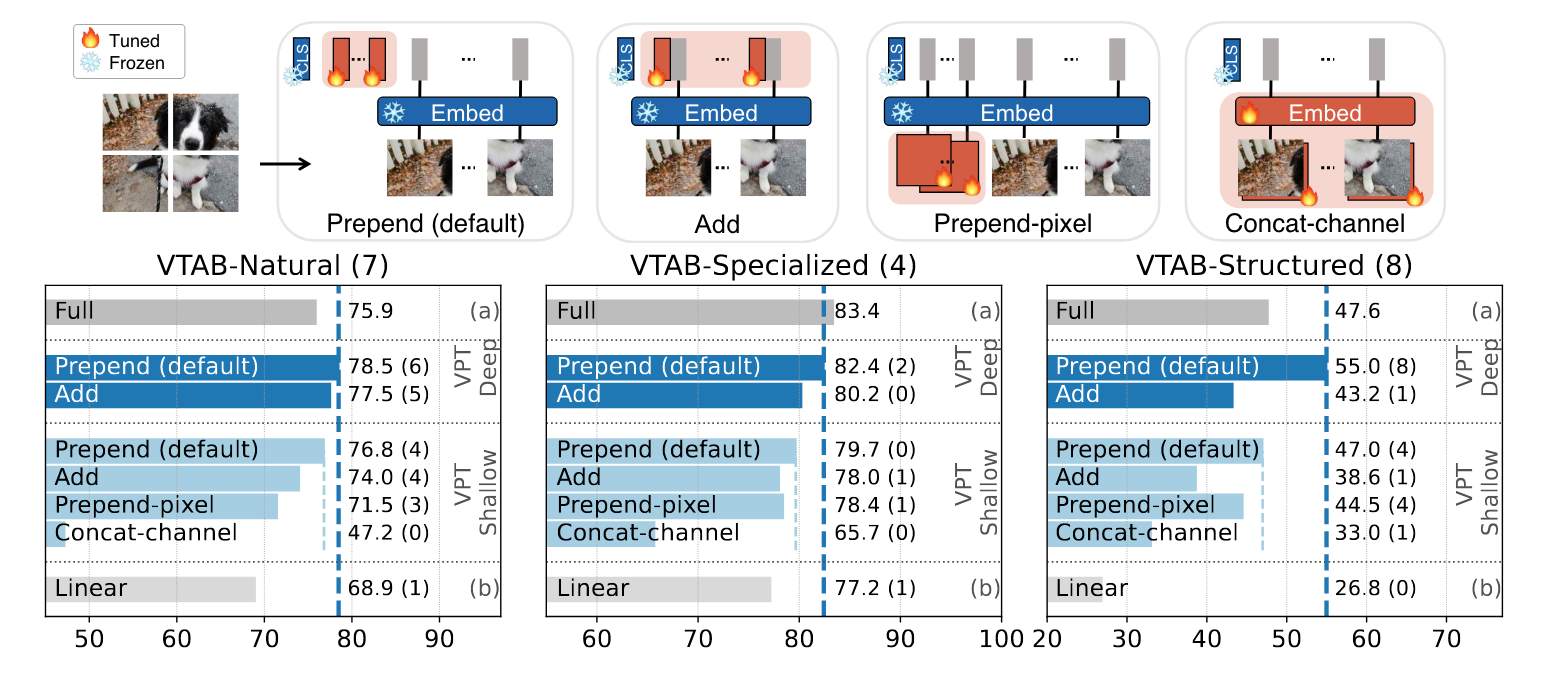
Introudction
이전에서는 Unsupervised Domain Adaptation(UDA)의 방법이 많이 제안이 되었습니다. UDA의 3개의 paradigms으로 접근을 하는데 첫번째의 경우에서는 statistical moments를 다른 feature distribution을 가깝게 하는 방법과, 두번째의 경우에서는 adversarial training을 통해서 추가적인 discriminator를 만드는 방법 그리고 마지막으로는 다양한 regularization을 target network에 넣어 self-training또는 entropy를 조절 하는 방법이 있습니다.
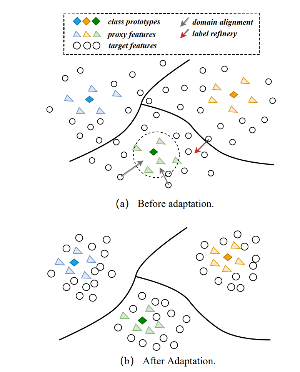
위의 방법을 motivation으로 이번 paper에서는 Source free domain Adaptation(SFDA)에 적용을 하였습니다. 이전의 SFDA의 일반적인 방법으로는 pseudo label을 만들어서 feature strcuture이나 모델의 예측을 내어서 target domain에 대해서 나타내었지만 이는 decision bounday에 noisy가 많이 있는 단점이 있습니다.
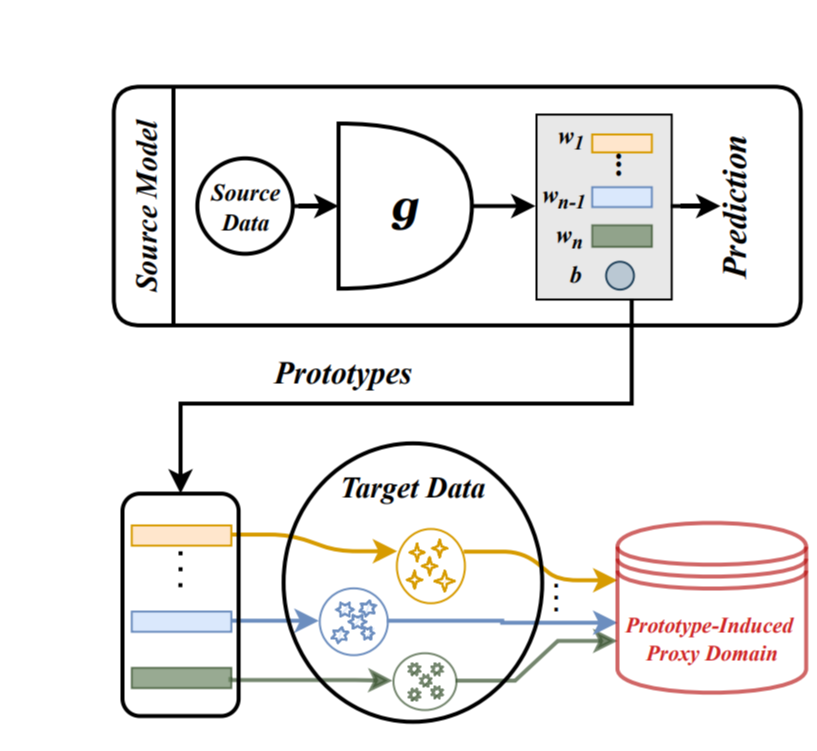
이를 통해 저자는 training에 label refinery할수 있는 Proxy based mixup(ProxyMixup)을 제안하였습니다. 이 방법의 경우 간단하게 source domain 과 traget domain에서 보지 못하였던 (unseen)데이터의 gap을 줄여주기 위해서 첫번째로 target domain에서 source image와 유사한 이미지를 뽑아내서어 proxy source domain에 만들어냅니다. 구체적으로 source classifier에 weight로 프로타입을 구하며 이를 중심으로 가까운 거리에 있는 image를 proxy source domain으로 구성하게 되어지게 되어집니다.
Pseudo label의 신뢰도를 올리기 위해서 frequency-weighted aggregation pseudo-labeling strategy(FA)를 제안을 하였으며 이는 sharpening, re-weighted, aggreation을 사용하여 Pseudo label을 만든 방법이며 ambiguous한 것에 대해서는 sharen하고 reweight를 하는 방식으로 변경하고 aggregation를 적용하여 unlabel에 대해서 label을 적용하게 되어진다
Method
Proxy Source Domain Construction by Prototypes
핵심 방법의 경우 SHOT의 paper와 모델과 유사하게 되어지며 source domain의 image는 접근 할 수 없음으로 source model의 weight를 바탕으로 prototype들을 뽑아내어지며 이를 바탕으로 proxy-domain을 만들어낸다. prototype과 마찬가지로 source classifier를 바탕으로 나온 target domain의 sample들도 함께 새로운 proxy-domain에 포함이 되어진다.
이떄 다른 점은 각 prototype과 가장 distance가 가까운 N개의 sample을 뽑아내고 class마다 똑같은 수의 sample를 찾아낸다. 그리고 같은 수의 sample맏 CE를 적용한다.
Proxy Source Domain Construction by Prototypes (FA)
Pseudo labeling를 적용했을 경우에서는 noisy가 많으며 특히나 unsupervised에서는 domain에 대한 dsitribution을 모르기 때문에 class가 imbalance하게 다른 class로 예측이 되어지는 경우도 많다. 이를 완화하기 위해서 저자는 새로운 pesudo label refinery strategy를 제안하였다.
이 전략중 하나는 soft Pesudo label를 사용하여서 접근을 하였으며 각 sample주위의 예측값의 평균을 하여 label를 refine을 한다. 이렇게 뽑은 데이터를 바탕으로 sharping을 하여 probability의 비중을 키우게 되어집니다.
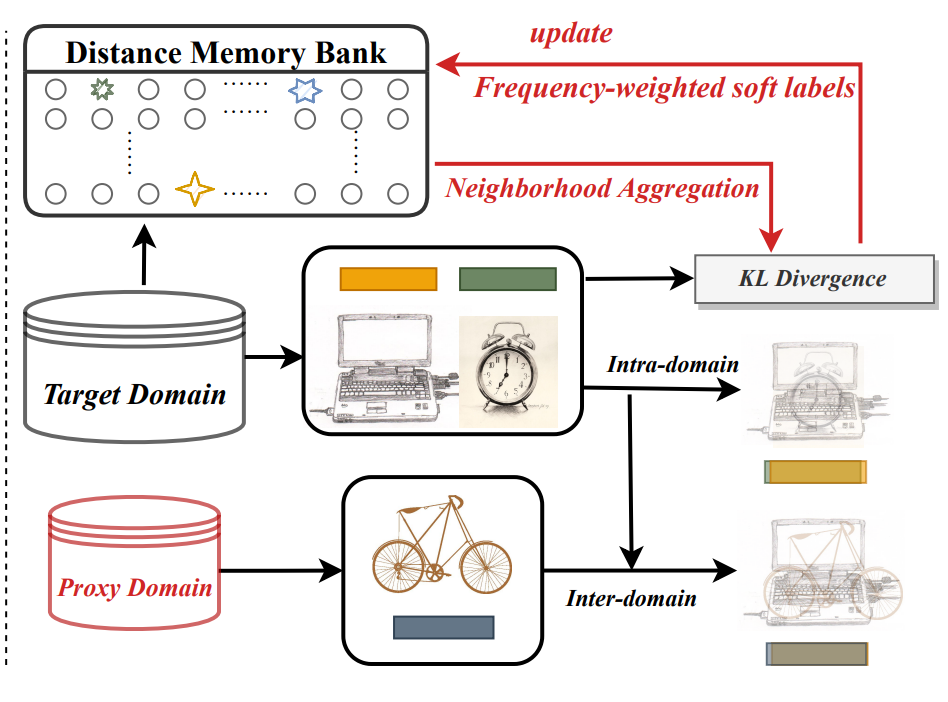
Domain Alignment by Mixup Training
위의 proxy domain과 target domain에서 나온 sample들을 domain을 mixup을 하게 되어진다.
이때 proxy domain과 target domain을 과 mixup을 하였을때 inter domain이라고 부르며 target domain과 target domain간의 mixup을 하는 건 intra domain이라고 부른다.

Expermient
Office-home에 대한 결과는 다음과 같다.

office-31의 경우도 다음과 같다.

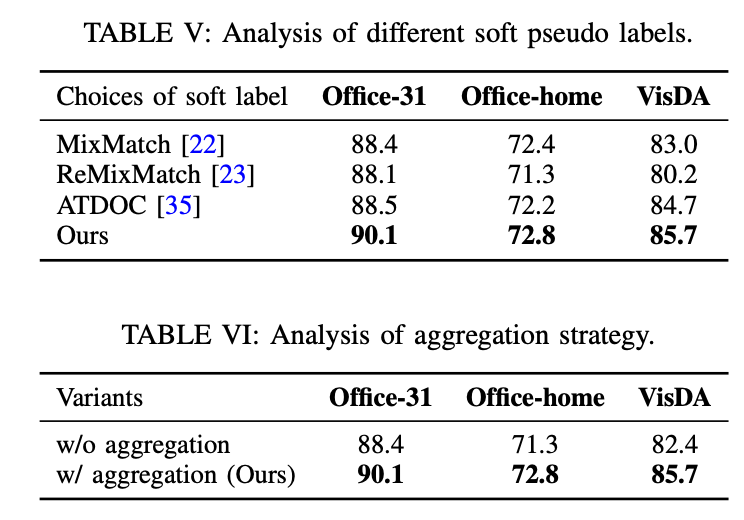
또한 기존의 pesudo label과의 차이를 비교를 하였으며 aggreation을 사용하고 난 전후의 성능 변화도 비교하였다.
Conclusion
이전의 방법과 비교하여 단순한 방법으로 적용을 하였으며 다른 domain으로 하여 mixup을 하였다는 novelty가 있음.